|
Pengcheng Xi I am a Senior Research Scientist at the National Research Council Canada (NRC) in Ottawa, where I lead projects at the intersection of AI, digital health, human motion, and robotics. I also serve as an Adjunct Research Professor at Carleton University. Previously, I held an Adjunct Assistant Professor position at the University of Waterloo. I received my PhD in Electrical and Computer Engineering from Carleton University, where I was co-advised by Rafik Goubran and Chang Shu. |

|
ResearchMy research spans machine learning, robotics, computer vision, and human-centered systems. I focus on human–autonomy teaming, studying human trust, situational awareness, and collaboration frameworks that enable people and intelligent systems to work together effectively. I work on human–robot interaction in assistive contexts, particularly for older adults, with emphasis on physical collaboration and human perception. This aligns with my research in 3D human motion generation, where we develop AI methods for realistic movement synthesis to support motion understanding and interaction design. In AI for digital health, I build multimodal sensing and analytics systems using audio, video, physiological signals, and data fusion for safety, wellbeing, and early detection. I also study diet and food understanding by integrating visual and linguistic cues with unsupervised learning and generative AI. Earlier work in 3D human modeling and anthropometric analysis informs my current efforts to advance human-centered AI and assistive technologies. Updates
|
|
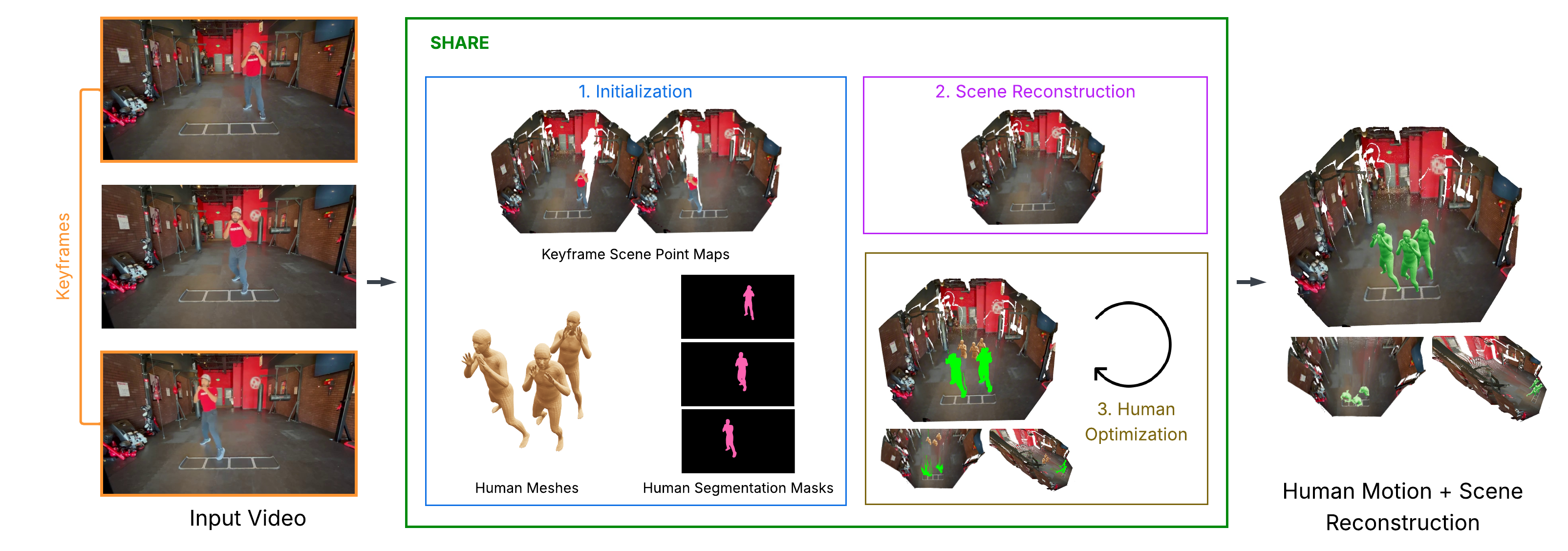
SHARE: Scene-Human Aligned Reconstruction
Accepted to SIGGRAPH Asia Technical Communications., 2025 SHARE is a new method for accurately placing 3D human motion into real scenes from a single monocular video. By aligning human meshes with scene geometry and ensuring temporal consistency, SHARE produces more realistic human–environment interactions and outperforms existing reconstruction approaches on both curated and in-the-wild videos. |

|
StableMotion: Training Motion Cleanup Models with Unpaired Corrupted Data
Accepted to SIGGRAPH Asia., 2025 project page We introduce StableMotion, a diffusion-based approach for cleaning corrupted motion capture data without the need for paired clean datasets. By leveraging simple motion quality indicators, our method trains directly on raw, artifact-prone mocap data and can both detect and fix errors at test time. Applied to a 245-hour SoccerMocap dataset, StableMotion reduces motion pops by 68% and frozen frames by 81%, outperforming state-of-the-art methods while preserving motion content. |

|
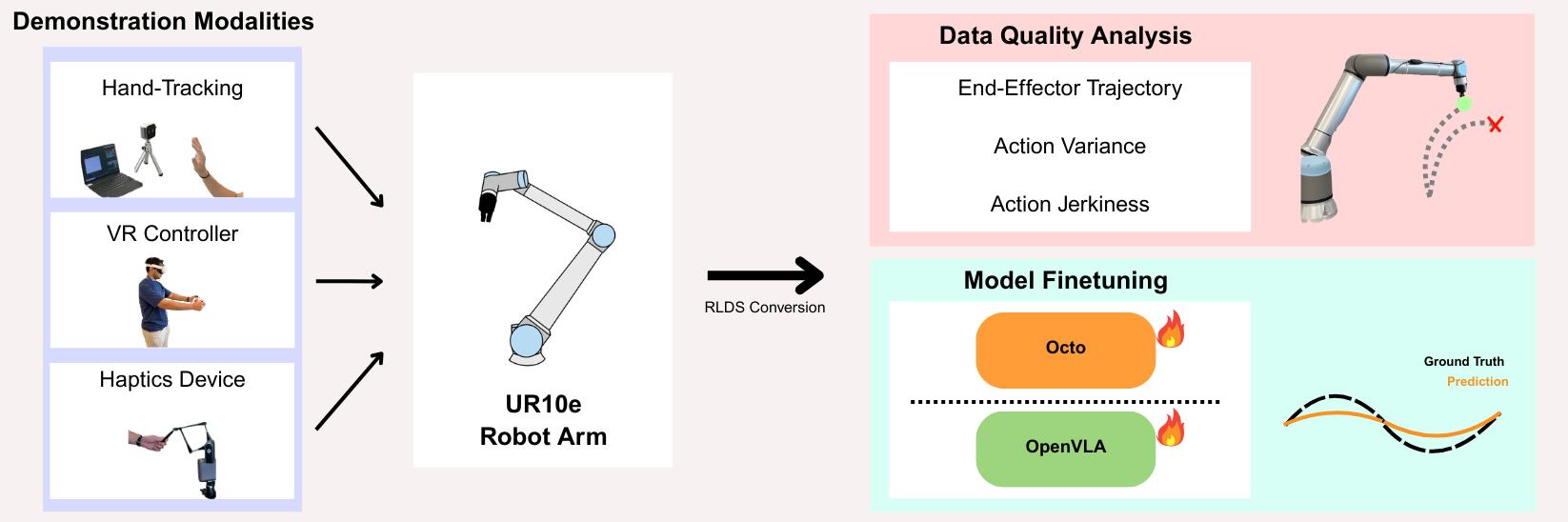
Design Decisions that Matter: Modality, State, and Action Horizon in Imitation Learning
Accepted to Data workshop @ CoRL., 2025 We investigate how different teleoperation interfaces shape the quality of robot learning data. In a study of 400 demonstrations on assistive tasks (wiping and lamp switching), we compare VR controllers and a haptic device, measuring operator workload with NASA-TLX and fine-tuning the Octo model under varying conditions. Our findings reveal clear modality-driven differences in data quality and downstream imitation learning performance, offering practical guidance for designing robot data collection strategies. |
|
Teleoperation Modalities for Assistive Learning
Accepted to ARC workshop @ HUMANOIDS., 2025 We present a comparative study on how different teleoperation modalities—markerless hand-tracking, VR controllers, and haptic devices—affect the quality of demonstrations and learned policies in imitation learning. Focusing on assistive manipulation tasks relevant to aging populations, we show that VR and haptic inputs provide more consistent demonstrations than hand-tracking alone. Moreover, combining modalities improves policy robustness and accuracy. |

|
Coughprint: Distilled Cough Representations From Speech Foundation Model Embeddings
IEEE Transactions on Instrumentation and Measurement, vol. 74, pp. 1-10, 2025, Art no. 2532210, doi: 10.1109/TIM.2025.3568985., 2025 This paper presents a lightweight, embedded cough analysis model for smart home systems, enabling accurate and privacy-preserving health monitoring. By distilling knowledge from a large speech foundation model, the student network achieves strong performance across multiple cough-related tasks while dramatically reducing model size and computation. The proposed approach generalizes well to unseen sound classes and eliminates the need for cloud-based audio processing. |

|
Food Degradation Analysis Using Multimodal Fuzzy Clustering
CVPR MetaFood Workshop, 2025 The paper presents an approach to modeling food degradation using fuzzy clustering, capturing the gradual nature of decay without relying on labeled data. It integrates traditional visual features with semantic features from Vision-Language Models to enable both low-level and high-level interpretation. |